Azure Failover and Resilience
Azure provides a highly resilient hosting platform, with significant built-in redundancy within a data centre, as well as the presence of more than 30 data centres across the world.
When first coming to Azure, it can be hard to understand what resilience you get automatically and what you might have to set up yourself.
This post provides a high-level overview of the principles. It is intended as an introduction to help you ask the right questions.
The usual starting point for a system is to host it in a single data centre. Azure is highly resilient even within a single data centre, but even so, all the data is continually backed up to a secondary data centre.
In the case of a complete failure of a data centre, the data can be restored to another data centre. This is not the same as automatic failover to another data centre; In order to get the data restored in the other data centre and get the system back up and running, you will have to do it yourself; Azure will (for the most part) not do this for you. How much work depends on how much preparatory work has been done and is primarily a business decision based on risk and cost.
Any conversation about failover is complicated by the fact that a system consists of different components, which can fail independently, which have different probability and impact and which require different failover strategies.
Before going into the details, it is important to understand that even the most basic setup in Azure has a very high level of resilience with each individual component typically having a guaranteed uptime of 99.95% or more. At the same time, data is continually backed up to a secondary data centre. In other words, even the most basic Azure setup has a level of resilience that is difficult and expensive to achieve with on-premise hosting.
In this post “failover” will refer to failing over between data centres.
As a general rule, any data you save in Azure, in databases, to disk or to other types of storage, is written to three different locations inside that one data centre and a single copy is written to another remote data centre as a backup. For example the London data centre backs up to Cardiff and the Amsterdam data centre backs up to Dublin etc.
Azure App Service has some built-in resilience so even with only a single compute node in your app hosting plan, you are pretty well protected from outages. With Cloud Services, you must ensure that you have at least two instances running at all times to ensure resilience. With Virtual Machines – you are much more on your own, though there are a number of things you can configure, such as Availability Sets etc. As a very general rule, to make reliability easier, avoid using VMs, use one of the managed options instead, when you can.
When you want to be able to fail over to another data centre, there are several options available to you. I have grouped them here under “Cold”, “Warm” and “Hot”. These are just convenience labels and may not correlate to other people’s definitions.
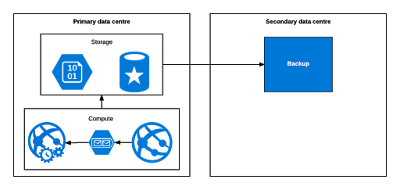
Your data is automatically backed up to another data centre. In the case of a failure of the primary data centre, you can go to the other data centre, set up your systems again, deploy everything and restore your database. Of course, the more automated your deployment is, the easier this will be.
You should be aware that while you can manually trigger a restore of SQL and CosmosDB databases, you cannot yourself trigger a “restore” of anything you put into Azure Storage. Microsoft has to do that by changing DNS entries and their SLA on that is up to 48 hours, last time I checked. There are things you can do to improve this, such as using read-access geo-redundant storage, but you will need to develop specifically to take advantage of that. Often, though, the data in Azure Storage is secondary to the main system and you may be able to live without that data for a day or two.
The exact frequency of database backups depends on the chosen database but is generally four hours or less.
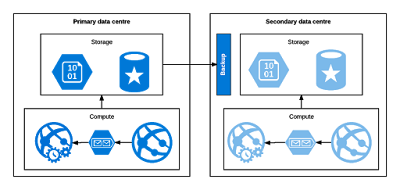 A Warm failover allows faster fail-over to a secondary data centre, but still requires manual intervention.
A Warm failover allows faster fail-over to a secondary data centre, but still requires manual intervention.
In order to reduce the time it takes to move to a secondary data centre, it is possible to prepare the infrastructure and have detailed plans in place. You can do this by configuring the whole system in the secondary data centre but not deploy anything to it; For many services you can define it but just not deploy anything to it. Similarly, you can deploy VMs and then de-allocate them etc. An alternative is to create an ARM template, which will allow you to quickly create a whole environment in Azure.
You should also write plans and scripts so you can quickly restore the databases and direct traffic to the other data centre etc. It may also require periodic testing of the plans.
Finally, you should make sure your DNS is set up with a short enough TTL that you can quickly move traffic to the new websites.
Document storage, such as files, may in the Warm scenario still take up to 48 hours to be made available in the other data centre.
 A Hot failover will automatically fail over to a secondary data centre if the primary data centre fails, in whole or in part.
A Hot failover will automatically fail over to a secondary data centre if the primary data centre fails, in whole or in part.
In practice, there are many different components to a system and it usually makes sense to only have hot failover in place for some of the components. A bespoke cost/benefit exercise should be carried out where hot failover is desired.
The primary things to consider;
As a general rule, you have to pay for two copies of your database and you may have to use a more expensive service tier.
In the case of CosmosDB, it may be required to consider consistency levels and the system may need to be adapted to deal with this.
Where required, Azure do provide ways to have direct access to a read-only copy in the secondary data centre. This can be utilised to build a very high level of resilience, but it requires explicit programming in your software to take advantage of this.
This does, however, mean that the queues can be a single point of failure; if the queue service fails, you can no longer enqueue messages.
From NewOrbit’s many years of working with Azure, it is clear that Microsoft are very aware of the crucial importance queues play in many systems and they have worked very hard to make them extremely resilient; Despite very extensive usage, NewOrbit has never experienced a failure with “storage queues” and has only experienced an issue with “service bus queues” on a single occasion in 2013.
It is possible to implement failover for queues and NewOrbit has done that before. There are different approaches that can be taken and Service Bus Queues have some native support for failover, though it does require programming to take full advantage of it.
If you need to report on your overall SLA, it is important to understand how to combine them. If you have, say, an Azure App Service with 99.95% SLA and an Azure SQL database with a 99.99% SLA then the overall SLA for both to be up is (99.95% x 99.99%) = 99.94%. This obviously compounds with more components.
On the other hand, adding a hot failover App Service in another data centre using Traffic Manager means you now have a better than 99.95% expected SLA for the App Service component. However, calculating the actual SLA is not practical due to the presence of “systemic risk”; There is one risk of a single data centre going down and a separate risk of a worldwide outage of Azure App Services.
When first coming to Azure, it can be hard to understand what resilience you get automatically and what you might have to set up yourself.
This post provides a high-level overview of the principles. It is intended as an introduction to help you ask the right questions.
The usual starting point for a system is to host it in a single data centre. Azure is highly resilient even within a single data centre, but even so, all the data is continually backed up to a secondary data centre.
In the case of a complete failure of a data centre, the data can be restored to another data centre. This is not the same as automatic failover to another data centre; In order to get the data restored in the other data centre and get the system back up and running, you will have to do it yourself; Azure will (for the most part) not do this for you. How much work depends on how much preparatory work has been done and is primarily a business decision based on risk and cost.
Any conversation about failover is complicated by the fact that a system consists of different components, which can fail independently, which have different probability and impact and which require different failover strategies.
Before going into the details, it is important to understand that even the most basic setup in Azure has a very high level of resilience with each individual component typically having a guaranteed uptime of 99.95% or more. At the same time, data is continually backed up to a secondary data centre. In other words, even the most basic Azure setup has a level of resilience that is difficult and expensive to achieve with on-premise hosting.
In this post “failover” will refer to failing over between data centres.
Resilience in a single data centre
Azure Data Centres are built in a modular way, meaning that each data centre can be thought of as many smaller data centres built next to each other. This means that your data and system will be physically spread over different parts of the data centre, in turn meaning that even if an entire part of the data centre fails, you are unlikely to notice.
Physically, all Azure data centres have multiple redundant power grid connections, multiple redundant internet connections, redundant backup generators, batteries and so on and so forth.As a general rule, any data you save in Azure, in databases, to disk or to other types of storage, is written to three different locations inside that one data centre and a single copy is written to another remote data centre as a backup. For example the London data centre backs up to Cardiff and the Amsterdam data centre backs up to Dublin etc.
Azure App Service has some built-in resilience so even with only a single compute node in your app hosting plan, you are pretty well protected from outages. With Cloud Services, you must ensure that you have at least two instances running at all times to ensure resilience. With Virtual Machines – you are much more on your own, though there are a number of things you can configure, such as Availability Sets etc. As a very general rule, to make reliability easier, avoid using VMs, use one of the managed options instead, when you can.
When you want to be able to fail over to another data centre, there are several options available to you. I have grouped them here under “Cold”, “Warm” and “Hot”. These are just convenience labels and may not correlate to other people’s definitions.
Cold

A Cold failover is what you get by default.
You should be aware that while you can manually trigger a restore of SQL and CosmosDB databases, you cannot yourself trigger a “restore” of anything you put into Azure Storage. Microsoft has to do that by changing DNS entries and their SLA on that is up to 48 hours, last time I checked. There are things you can do to improve this, such as using read-access geo-redundant storage, but you will need to develop specifically to take advantage of that. Often, though, the data in Azure Storage is secondary to the main system and you may be able to live without that data for a day or two.
The exact frequency of database backups depends on the chosen database but is generally four hours or less.
Warm

In order to reduce the time it takes to move to a secondary data centre, it is possible to prepare the infrastructure and have detailed plans in place. You can do this by configuring the whole system in the secondary data centre but not deploy anything to it; For many services you can define it but just not deploy anything to it. Similarly, you can deploy VMs and then de-allocate them etc. An alternative is to create an ARM template, which will allow you to quickly create a whole environment in Azure.
You should also write plans and scripts so you can quickly restore the databases and direct traffic to the other data centre etc. It may also require periodic testing of the plans.
Finally, you should make sure your DNS is set up with a short enough TTL that you can quickly move traffic to the new websites.
Document storage, such as files, may in the Warm scenario still take up to 48 hours to be made available in the other data centre.
Hot

In practice, there are many different components to a system and it usually makes sense to only have hot failover in place for some of the components. A bespoke cost/benefit exercise should be carried out where hot failover is desired.
The primary things to consider;
Web site failover
It is possible to deploy the front-end web servers to more than one data centre and use Traffic Manager to automatically direct traffic between the two. This works with most kinds of web hosting you can do in Azure. This means that if the websites in one data centre fails, requests will automatically be served by the other data centre, usually within 1 minute. The main costs are in paying for the extra server(s) and the added complexity in every deployment.Database failover
Azure offers hot failover for both Azure SQL and CosmosDB, the two main databases. With this failover, Azure will dynamically fail over to a secondary data centre in case of a failure and/or serve requests from both data centres. The mechanisms used by SQL Azure and CosmosDB are fundamentally different and will require different approaches.As a general rule, you have to pay for two copies of your database and you may have to use a more expensive service tier.
In the case of CosmosDB, it may be required to consider consistency levels and the system may need to be adapted to deal with this.
Storage failover
It is common to store files and certain other types of data in Azure Storage. By default, data is backed up to another data centre (though this can be disabled when not required). However, Azure is in control of enabling access to the backup in case of a failure and the SLA is up to 48 hours. In many cases, this is acceptable as the loss of access to historical files may be considered a service degradation rather than a failure.Where required, Azure do provide ways to have direct access to a read-only copy in the secondary data centre. This can be utilised to build a very high level of resilience, but it requires explicit programming in your software to take advantage of this.
Queue failover
In an effort to increase resilience and scalability, it is common to use queues in systems; Rather than do something straight away, the system will put a message on a queue and a background job will then process this. This design has many benefits, including automatic retrying, resilience to external systems being down and significant scale benefits as sudden peaks in demand just causes queues to get longer for a little while.This does, however, mean that the queues can be a single point of failure; if the queue service fails, you can no longer enqueue messages.
From NewOrbit’s many years of working with Azure, it is clear that Microsoft are very aware of the crucial importance queues play in many systems and they have worked very hard to make them extremely resilient; Despite very extensive usage, NewOrbit has never experienced a failure with “storage queues” and has only experienced an issue with “service bus queues” on a single occasion in 2013.
It is possible to implement failover for queues and NewOrbit has done that before. There are different approaches that can be taken and Service Bus Queues have some native support for failover, though it does require programming to take full advantage of it.
Other items
There are many other items that can be used in Azure, including virtual machines. For most of these items, a bespoke failover strategy is required to achieve hot failover.More SLA details
The individual SLAs for all Azure services can be found at https://azure.microsoft.com/en-gb/support/legal/sla/If you need to report on your overall SLA, it is important to understand how to combine them. If you have, say, an Azure App Service with 99.95% SLA and an Azure SQL database with a 99.99% SLA then the overall SLA for both to be up is (99.95% x 99.99%) = 99.94%. This obviously compounds with more components.
On the other hand, adding a hot failover App Service in another data centre using Traffic Manager means you now have a better than 99.95% expected SLA for the App Service component. However, calculating the actual SLA is not practical due to the presence of “systemic risk”; There is one risk of a single data centre going down and a separate risk of a worldwide outage of Azure App Services.
Help?
If you have a quick question, ping me on twitter.
If you want more extensive advice and guidance, my company NewOrbit offers help to other companies who are moving to Azure. We have been building systems on Azure since 2011 and are a Microsoft Cloud Gold Partner.